Taking the strain out of strain optimisation
The advantages of lab automation for high throughput microbiology
Strain optimisation is a crucial step in enhancing performance within various industrial and research applications. By fine-tuning strains, resistance to harsh environmental conditions and toxic substances can be increased, ensuring strains can thrive in challenging production environments. Optimisation also allows for significant improvements in growth rates, metabolic profile, and yield of desired products.
Foundational to strain optimisation is the generation of strain libraries and high throughput screening. If you are concerned that any of these workflows could become a bottleneck in your lab, read on and we’ll take you through the benefits and pitfalls of automation.
Lab automation goals: start small, target bottlenecks
When I close my eyes and imagine my dream automated lab, I picture myself in the centre of a bright space, surrounded by sleek instruments with helper drones whizzing round moving materials and samples between them, and helper robots (cobots) at my beck and call, adapting to me and the way that I like to work. For me, this would be the ultimate, flexible, automated lab. The reality is that achieving flexibility and full lab automation is incredibly difficult because these two goals are mutually exclusive. Our CEO, Harry Singer, coined the term ‘The Synbio Automation Dilemma’ to describe this phenomenon.
Instead of trying to automate everything at the same time, which is a prohibitively daunting prospect, it pays to focus on identifying and resolving bottlenecks with automation in an incremental fashion. The rate limiting step of any system (e.g. the throughput of a lab or workflow) are the bottlenecks and automating processes that are not bottlenecks will do little to increase productivity. To learn more about how to identify bottlenecks, see our prioritising bottlenecks guide.
Automating strain library generation: building a stronger foundation
At the heart of many microbiology projects lies the strain library—a collection of microbial strains often housed in multiwell plates. Libraries can include isolated wildtype strains in bioprospecting projects, mutagenised versions of the same parent strain to identify useful mutations or a collection of engineered strains harbouring different constructs.
The methodology for creating and maintaining these libraries will vary significantly based on the organisms used, whether or not genetic engineering is required and what the downstream applications that will use these libraries are. At its simplest, making libraries can be as simple as isolating individual colonies from agar into separate wells of multiwell plate but complex procedures can involve a series of liquid handling, incubation, sequencing and screening steps.
Humans are endlessly adaptive and creating libraries manually offers the ultimate level of flexibility. However, manual creation and management of strain libraries can be fraught with challenges. The risk of human error, the time-intensive nature of the process, and the difficulty in maintaining consistent quality across hundreds or even thousands of strains can lead to significant delays and unreliable data. The latter problem is of particular concern given that up to 50% of scientists have failed to reproduce their own experiments and experimental error is a major source of problems in reproducibility (Baker, 2016, Nature). Underlying problems with a library may not be easily detected but can have a major impact on the success of downstream processes such as high throughput screening.
If the creation and management of strain libraries is relatively routine, the drawbacks of manually processing strains can easily outweigh any advantage of flexibility. Automated strain library generation allows labs to scale up their efforts significantly, creating libraries that contain many thousands of strains with unparalleled precision and consistency. Automated instruments, such as liquid handling robots and colony picking robots, can perform repetitive tasks with accuracy, ensuring that each strain is correctly identified and stored. These systems also facilitate the generation of detailed maps that describe the locations of strains within the library, making it easier to track and analyse phenotypic data later on.
Automated high-throughput screening: converting more haystacks into more needles
Screening strains is a routine operation in microbiology and synthetic biology, enabling workers to identify transformants or the most promising candidates based on a set of criteria. Screening methods are diverse but can be characterised as taking a collection (or library) of strains with genetic diversity and applying a selection. The selection can be applied indirectly by changing the biotic or abiotic conditions (e.g. increasing the temperature to screen for heat tolerance) or directly by choosing candidates based on a measured parameter of the strain (yield, growth rate, fluorescence…)
Low and medium throughput screening can be achieved relatively easily using manual methods which may be sufficient in some applications. However, there are three occasions when this is suboptimal: when the candidates are rare, when the pool of candidates is very large or when this activity is routine. Using the analogy of trying to find a needle in a haystack, if there aren’t many needles to look for, the haystack is too big or there are an indefinite number of haystacks to search, manually looking for needles can be too tedious, slow and expensive. This is when high throughput screening (HTS) is required which usually necessitates automation to get the required levels of throughput and accuracy. Automated HTS systems can work around the clock, processing hundreds of samples simultaneously and generating vast amounts of data in a fraction of the time it would take manually.
There is a huge array of screening methods including the use of biosensors (fluorescent, luminescent, or colorimetric), -omic profiling (transcriptomic, proteomic, metabolomic), colony growth and morphology characteristics (growth rate, size, colour, topological features). When screening based on colony morphology and growth, automating the screening process can be as simple as using a colony picker which has colony phenotyping functionality.
Other screening workflows may involve the integration of flow cytometers, mass spectrometers, spectrophotometers and other instruments which are outside of the specialism of Singer Instruments. Speak with an integration provider to find out more how you can automate your custom workflows to give you the throughput and accuracy to boost the performance of your workflow.
Automated strain optimisation: rational design leveraged with evolution
Approaches to optimise strains can be grouped into rational and evolutionary engineering approaches. Rational approaches seek to engineer strains based on mechanistic understanding such as inserting heterologous genes into an organism to transfer functionality. Evolutionary approaches such as adaptive laboratory evolution (ALE) do not require a priori knowledge of the underlying mechanisms and instead leverage generic diversity and selection pressures to make improvements. Often rational design is used to introduce new functionality which is then fine tuned using ALE to optimise the strain further. A remarkable example of this was the introduction of genes into Pichia pastoris yeast converting it from a heterotroph into a CO2-utilising autotroph (Gassler et al., 2020). The performance of the autotrophic capability was then improved using ALE.
Arguably the most difficult part of rational design is deciphering the mechanics of cellular systems and designing synthetic systems based on this knowledge. Computational models including deep learning are employed to speed up this learning exercise but the ‘design’ element of rational design is still very much a human process. The engineering element of rational design can certainly be automated. For example, a platform utilising liquid handling robots has been used to fully automate the construction of strains of the industrial bacterium Corynebacterium glutamicum based on rational (human) design (Tenhaef et al., 2021). Automating tedious manual processes that can be automated frees up people to do the stimulating work that robots simply can’t perform.
It takes a great degree of knowledge of the mechanics of a pathway to be able to introduce it de novo into a different organism. However, the sheer complexity of cellular systems means it is very difficult to model let alone engineer how to best optimise the process. This is where ALE is particularly powerful. By subjecting microbial strains to selective pressures over time, ALE drives the evolution of desired traits, mimicking the process of natural selection in a controlled environment. ALE is often implemented as a combination of strain library generation (to increase diversity) and strain screening (selection pressure). As described in this article, both of these processes can be performed in a multitude of ways depending on the organism, the phenotype being improved and the application. Below is an example of how ALE can be automated using an agar-based selection pressures with additional selection based on colony phenotype.
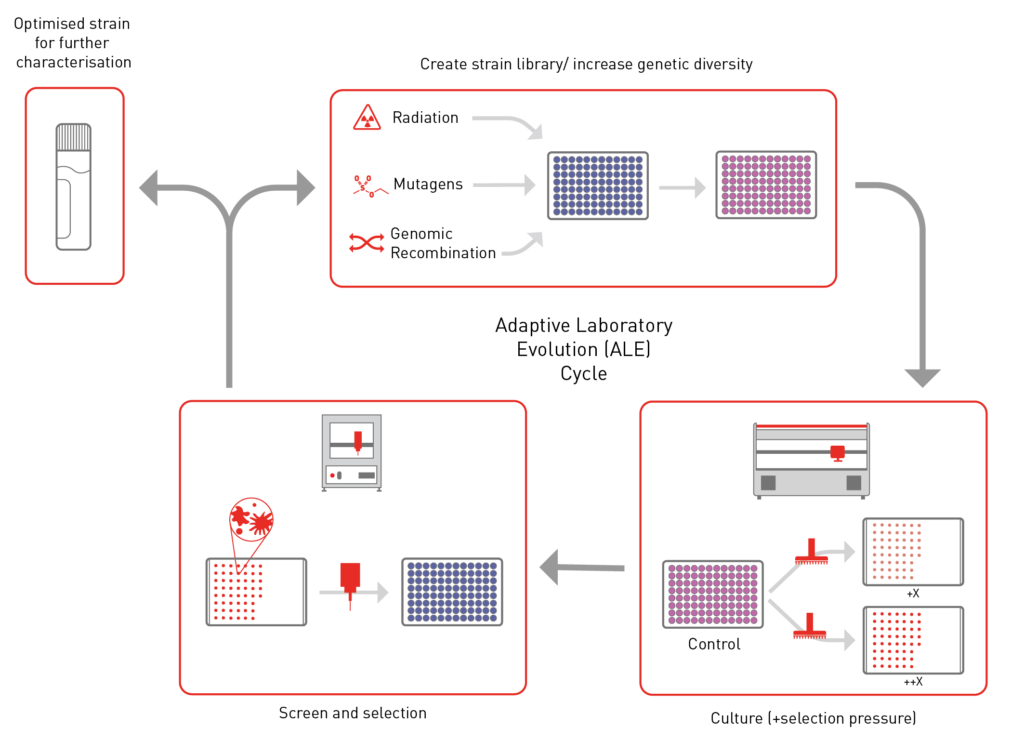
Figure 1: Automated adaptive laboratory evolution (ALE) workflow. In this example, a library of strains with genetic diversity is automatically printed onto agar containing a given compound (e.g. ethanol) at 2 different concentrations using ROTOR+. After incubation, PIXL colony picking robot is used to image the plates to look for candidates that meet a given criteria (e.g. bigger colonies > tolerance). PIXL is then used to pick candidates. Candidates can be characterised further or subject to treatments to increase genetic diversity before further cycles of ALE are performed.
Conclusion
Automating key processes like strain library generation, high-throughput screening, and strain optimisation can increase efficiency, accuracy, and scalability. While the flexibility of manual methods can be valuable, the consistency and throughput provided by automation are crucial, especially as workflows become routine, grow in complexity and scale. Library generation and screening workflows can be relatively simple (e.g. colony picking) or involve a wide range of sub processes including phenotyping, cell sorting, mass spectroscopy and a myriad of other techniques. Most workflows can be fully, or partially automated, and additional automation can often be incorporated into the system later as bottlenecks are tackled sequentially. Strain optimisation often requires elements of library generation and screening and benefits from the same advantages of automation. A key advantage of automating repetitive and monotonous physical tasks is to free up humans to do the stimulating work that requires flexibility and human insight such as rational design.
Don’t fall victim to the failed promise of lab automation
Avoid the costly mistake of investing in a device that ends up in your laboratory graveyard.
Discover the key considerations for evaluating a colony picker in our article: How to Pick a Picker.

Phil Kirk PhD | Senior Scientist
Phil heads up our Research team, combining his biological knowledge, programming experience and engineering skills to push our robots to their limits and leading experimental work to back up their use in a variety of applications and settings.
He has a background in plant science and biotechnology, and close to a decade of laboratory experience. Hence, he’s as happy wielding a micropipette as a screwdriver, loves cracking complex scientific problems, and is an absolute whizz at designing an R-script!
By ensuring our innovations do what they are designed to do, Phil’s work contributes to more reliable robots, meaning more time our customers can spend performing the work that can’t be automated: creating, interpreting, and enjoying science!