The Synbio Automation Dilemma
How smart labs avoid common automation pitfalls by building incrementally
Who’s this article for?
“It took two years to get our automated biofoundry installed, and it still doesn’t properly work!”
Anonymous Biofoundry
Sadly I’ve heard this on multiple occasions! So… I’m really keen to help biotechs avoid some of the common pitfalls associated with adopting lab automation, aka ‘The Synbio Automation Dilemma’.
So, if you’re part of an ambitious, well-funded lab at the beginning of your automation journey: ignore this article at your peril! Or, if you’re an experienced lab automation guru, then we’d love to hear what you think.
What’s the dilemma?
The dilemma is that high levels of lab automation and flexibility are mutually exclusive. Unless you’re Ginkgo Bioworks, highly flexible, integrated laboratory automation is not financially viable.
Yes, that is a depressing bombshell. If you were super excited about starting a biofoundry by tackling all the automation first, we strongly encourage you to think again.
I know, you’ve read articles like Automating the design-build-test-learn cycle towards next-generation bacterial cell factories. Yes it IS doable. But over time, and with incremental experience.
Lab automation is a long and very expensive journey. We think that the most successful biofoundries (including Ginkgo) start with an appreciation of the complexities of lab integration.
They start by applying automation to a very specific workflow, and building upon it. Sustainably. One manageable automation extension at a time. This article will attempt to explain.
What is Integrated Lab Automation?
Integrated lab automation is a term that describes two or more laboratory automation devices being linked together with some coordination software and one or more robotic arms (or similar) to pass labware between the devices. It’s actually pretty complicated and most labs employ an Integration Provider to help with this as a service.
Why is it so difficult?
To illustrate this, let’s have a look at the hardware and software architecture required to integrate just two laboratory devices. This ‘tech stack’ could indeed reside within a bigger stack that includes upstream technologies, like biological design and/or design of experiment software. Will Kanine (former Opentrons) wrote a nice article about this for Synbiobeta called The Synbio Stack Part 1. But here we’re just looking at the process execution and data analytics part of the stack. Let’s break it down.
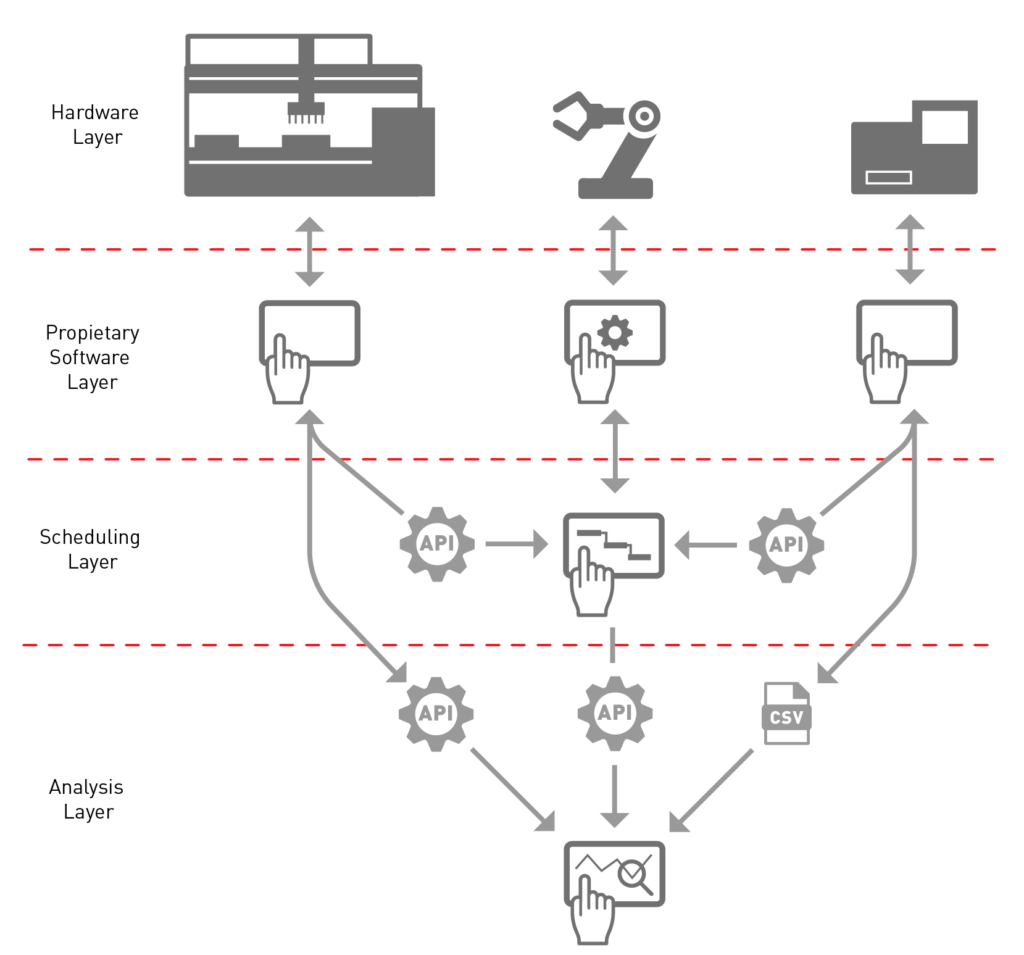
The hardware
There’s a Big Device at the top left of the diagram, a Small Device top right, and a robotic arm in the middle to shuffle automation-friendly plates between the devices. Each device has its own proprietary software that you will have to master.
The device software
The robotic arm software will enable you to configure and program the robot. It’s not that difficult, see Robot vs Cobot, FIGHT! Your integration provider will do the configuration, leaving you to just re-teach the robot from time to time.
The Big Device’s software probably has a lot of functionality, especially if it’s a liquid handler. The simplest way to get this automated is to optimise a very specific protocol and save it with all of its settings. It’s this method and settings ‘profile’ that will be called upon by the Scheduling Software. Let’s call it DO SCIENCE.
The Small Device might be significantly simpler, but still might require optimising. Again, you’ll have to save the settings as a profile for recall. Let’s call this DO MORE SCIENCE.
The scheduling software
Then there’s some Scheduling Software. At its most basic, this is an interface that has at least three elements: Configuration, Workflow Design and Run. Or something similar. It might also have Simulation Mode, and a Batch Planning Mode. It can be big. And very powerful. And comes with some serious responsibilities.
Anyway, most of the configuration stuff should be taken care of by your Automation Provider. They should help with user provisioning and permissions. They will also have to write a Device Driver, a translation layer to allow the Scheduling Software to talk to the API of each of the devices. You what?
APIs and device drivers
API stands for Application Programming Interface. It’s an elegant way for two or more computer programs to communicate with each other. It is the responsibility of the device manufacturer to write and document their device’s API. And, importantly, to communicate any changes!
At its most basic, the API exposes methods like INITIALISE, SHUT DOWN, DO SCIENCE, DO MORE SCIENCE, GET DATA, CHANGE SETTINGS. The amount of functionality exposed depends on the device manufacturer. Usually it’s just pretty abstract, high-level stuff.
Then there’s a Device Driver. This is the responsibility of the Integration Provider. A simple Device Driver will map methods in the API to functions that can be called upon in the Scheduling Software. A more complex Device Driver can also expose settings to increase flexibility from the Scheduling Software. However, the more settings that are exposed, the more complicated and costly it becomes, and the more maintenance may be required.
A stable API with infrequent releases is critical for integrated systems. Every time there’s a software update with a new method or setting, or a method changes, it forces the Integration Provider to have to update the Device Driver.
How much investment does it take to implement and support all of this? Good question, but I’ve left that for another article: Lab Automation: This Checklist Could Save You $100,000s.
Workflow design
This is more fun. Access to this part of the software might depend on your User Provisioning and permissions. Often it’s a drag-and-drop interface. It shows all the functionality from each piece of Hardware that’s exposed through their respective Device Driver. And it shows a bunch of cool functionality that can do other stuff. Stuff like dialogue pop-ups for manual operations like loading, barcode scanning or instructions for taking some labware to an unconnected device. Other stuff might include triggering runtime events like smartphone notifications. Some Workflow Design software can also support conditional workflows that branch and go one way or another based on the outcome of a previous stage.
An Integration Provider will not leave you alone with this, they will likely design your first workflow which you can then optimise over time, or use as an example for new workflows.
Runtime interface
This is a cleaner, skinnier interface, possibly accessible by more staff depending on your user provisioning and permissions. It should allow the user to select from one or more workflows and run them. As described above, it may prompt at stages for user intervention. It may even have exposed some device settings for a bit of flexibility within the workflow. It may also monitor real-time progress, and help guide a user through recovery should something go wrong.
Data analysis
Remember that diagram above? Right at the bottom in the Analysis Layer there’s an icon that represents your LIMS (Laboratory Information Management System) or Data Analysis Software. In a similar way to your Scheduling Software, this needs to communicate with your devices’ APIs through Device Drivers in order to get your results. A less robust way of doing this is to trigger data input by depositing the results from a certain device in a certain format into a particular folder somewhere. It’s a surprisingly common hack, but not recommended because of its lack of resilience. For example, if somebody inadvertently messes around with the wrong file structures it will stop working.
System fragility
Looking back at the system architecture, have a look at all the APIs in the Scheduling and Analysis Layers. I haven’t shown it, but each connection requires a Device Driver, as explained previously. In this particular example the system would need a Device Driver for each of those four APIs and one Device Driver triggered by a CSV file. That’s five of them in total.
Sadly, Device Driver updates often happen retrospectively. The system stops working for some reason. The Integration Provider is called in to troubleshoot. They eventually find out that a Device Manufacturer has performed a software update that changed the API. They have to get the new API documentation from the Device Manufacturer (if it exists) to understand these changes. Then they have to reprogram, upload and reconfigure the Device Driver. Then you might have to re-optimise and re-validate the affected workflow(s).
This applies for every hardware device connected. The bigger an integration gets, the more fragile it becomes to change! Should API updates change methods or data structures, then Device Drivers will have to be updated.
The common solution? Turn off software updates. Be weary of change. It’s part of the paradox of lab automation.
What if I want access to more data or to run another method on one of the devices? You’ll have to get the Device Drivers updated. What if I want to expose some settings for flexibility? You’ll have to get the Device Drivers updated. What if I want the latest software update for Big Device? Unless Big Device maintains API backwards compatibility, you’ll have to get the Device Driver updated.
But I still want a flexible biofoundry
You still want to automate your flexible design-build-test-learn cycle. Of course you do. But I hope you have started to get an understanding of the complexities required to perform just a single, inflexible, automated workflow across a small number of devices. I hope you start simple. Start with a specific workflow that will have the most impact. And then build out your automation capabilities and flexibility. And do it one increment at a time. It’s a fantastic learning curve.
Oh, and another thing: Choose your automation devices wisely. Check out Lab Automation: This checklist could save you $100,000s.
Thanks for reading!

Harry Singer PhD | CEO
This is a message to all of the frustrated lab automation techies out there. I can’t promise you that Singer Instruments won’t ever update our APIs. But we’ll always give you some warning. We’ll do our very best to maintain backwards compatibility. We’ll do our very best to make our products robot-friendly. We promise to make our API documentation comprehensive, accessible and well maintained. And we’ll always support you if you give us a call.
Oh, and if you disagree with anything I’ve written here, please let me know. I’ve got a growth mindset!
Ready to consider your automating options more closely?
Scale up your microbial research with our High-throughput screening solutions.